

Machine Learning for Dummies
Thanks to this centuries’ big data hype, machine learning has quickly become one of the most up and coming academic disciplines in today’s society. The sheer amount of papers, books and articles concerning machine learning algorithms that are now being published every year indicate that the field plays a very significant role in a vast number of industries. But what exactly is machine learning? Where does it originate from? And which specific algorithms should you definitely be familiar with? It is time to take a walk down machine learning street!
As often happens when a topic becomes such a hype, there exist tons of definitions for machine learning which all differ from another. The Oxford dictionary describes it as the capacity of a computer to learn from experience: ‘to modify the computer’s processing on the basis of newly acquired information.’ Wikipedia prefers to phrase it as ‘a field of computer science that gives computers the ability to learn without being explicitly programmed.’ Nevertheless, (almost) all definitions agree on one thing: machine learning requires a computer, data and a self-learning algorithm.
From checkers to deep learning
The term machine learning was first used in 1959, when Arthur Samuel (a pioneer in the field of artificial intelligence and computer gaming) published a paper regarding his self-learning checkers program (Samuel, 1959). Samuel believed that teaching computers to play games was very fruitful for developing tactics appropriate to general problems, and he thought checkers would make a good example (as it requires some strategy, but still remains quite simple). However, one could argue that the basics of machine learning had already been laid down even before 1959, as already in 1950, the scientist Alan Turing created the so-called Turing Test: an experiment to find out whether a machine is intelligent, where the computer passes if a human judge believes he is not conversing digitally with a machine but with a person.

Nonetheless, it is certain that the foundation of machine learning was made in the 1950s, after which many new algorithms and methods started to follow each other in rapid succession. In 1967 the next big step was made when the nearest neighbor algorithm was invented, which can be seen as the start of pattern recognition. For those of you who are not familiar with it, the goal of pattern recognition is to classify objects into a number of classes/categories, which is done based on shapes, forms or patterns in the data. There are numerous pattern recognition techniques, systems and applications that cover a broad scope of activities; examples can be found in speech recognition, stock exchange forecasts, classification of rocks and many more.
In the next decade, the 1970s, many more techniques for learning from data became available. However, due to computation limitations, almost all of these methods concerned linear relationships between the input and the output. It was only in the mid-1980s that regression and classification trees were first introduced (for more information about decision trees, check out the glossary!) and soon after also a non-linear extension to generalized linear models was brought to life, including a practical software implementation. This truly marked the start of statistical learning, which comprises supervised (with an output variable y) and unsupervised (without an output variable y) learning as well as prediction. As a result, many well-known machine learning techniques were discovered in the end of the previous millennium, such as random forests (see the glossary) and support vector machines.
As of today, machine learning is definitely an integral part of the statistical and programming fields. Who has not heard of buzz terms as big data, data mining and business analytics? Perhaps the hottest method amongst all current machine-learning methods is deep learning: a specialization within ML that is based on artificial neural networks. Neural networks were already discovered in 1957 and are inspired by the composition of biological brains, and especially the immense large amount of interconnection between neurons. Unlike actual brains though, these artificial neural networks have underlying layers, connection and directions. Deep learning combines these special types of neural networks with advanced computing power, and the result is a state-of-the-art method for identifying objects, images, words, sounds and so on.
Business hype
While machine learning started as an academic discipline, it has gained huge momentum in the corporate world as well. This can partially be explained by the massive growth of the total amount of available data: Arizona State University estimates show that the volume of business data worldwide, across all companies, doubles every 1.2 years. Thanks to this exponential rate, and the fact that much more powerful and user-friendly software systems have become available (just consider Python or R), machine learning has become very popular for most industries that work with large amounts of data. ML gives organizations the possibility to model faster, to analyze bigger and more complex data, and to learn additional insights besides the basics, and as a result, first can work more efficiently and gain a possible advantage over competitors who are not yet that advanced.
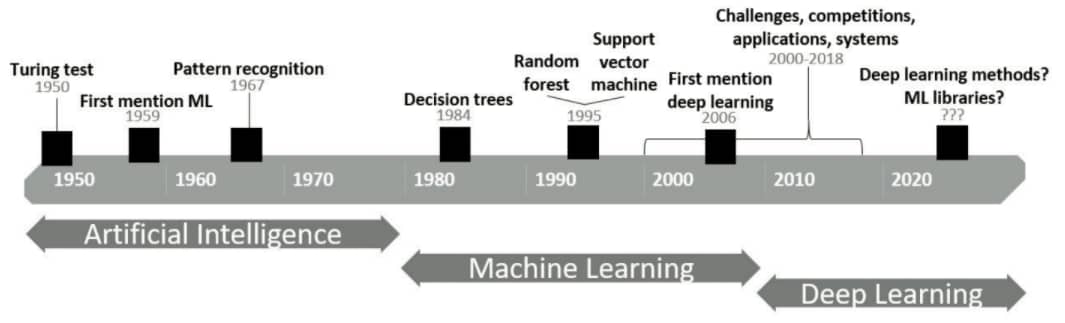 Click on the image above, to see the details of the timeline.
Click on the image above, to see the details of the timeline.
What’s next?
While there are already numerous techniques and algorithms in various aspects, it does not seem very plausible that machine learning will die out soon. On the contrary, many believe that we are only at the very humble beginning of the ML era. As more and more research teams from companies shift from traditional data techniques towards ML and even deep learning techniques, it is clear that data scientists will not have to be afraid of being unemployed any time soon. However, there is still much to discover in the theoretical aspect as well.
One of the fields in which we have only uncovered a tip of the iceberg is deep learning. There have only been a few years of research and studies in this field, but there is already a vast amount of promising network structures and algorithms. While deep neural networks have already outperformed plenty of other machine-learning methods (especially in problems related to vision and speech), there is not yet that much theoretical understanding for why these networks actually perform so well.
Besides more theoretical knowledge on newly-introduced methods, we can probably expect quite some development in machine-learning libraries. Not only is there an increase in algorithm-specific libraries/packages, but they are also becoming more user friendly, thereby making machine learning more accessible to the public. Clearly not everyone will be able to program gradient boosting machines or neural networks, but such tools can enable data scientists to help automate tasks such as hyperparameter tuning, and can also help non-programmers to implement (basic) machine-learning methods more easily.
In conclusion, there are many speculations about the future of machine learning, varying from optimistic views (e.g. perfectly operating self-driving cars) to rather depressing views (e.g. evil machines taking over the world). While both of these examples seem to be quite a long way down the road, only time can tell!
References
Samuel, A. L. (1959). Some studies in machine learning using the game of checkers. IBM Journal of Research and Development, Vol. 3, No.3. July, 1959.
Glossary
Bias variance tradeoff
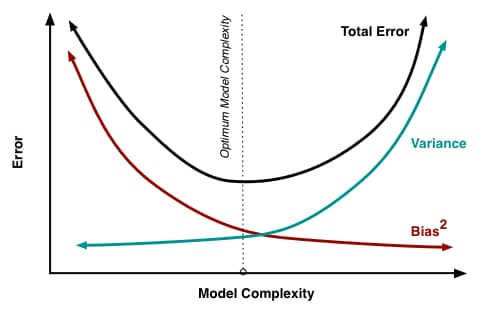
A prediction model involves a reducible and an irreducible error, where the first type consists of the model’s bias and variance. A very complex model often has low bias but high variance (as the underlying structure is very flexible and follows the noise too closely), whereas a very simple model often has low variance but high bias (as the underlying structure is not flexible enough to capture all relevant relations). As a result, there exists a tradeoff between a model’s ability to minimize bias and variance.
A decent machine-learning method takes this tradeoff into account. It is therefore common to split the observations into two different subsets: a training set (also called in-sample observations) upon which the model is fit and a test set (also called out-of-sample observations) upon which the model is evaluated upon. As a result, models that are unnecessarily complex or inaccurately simple will have a higher total error when tested on the out-of-sample observations. A visualization of the tradeoff can be found in the figure below.
Decision trees
Decision tree algorithms use a decision tree to predict the outcome of target variables by learning splitting rules from the dependent variables in prior data; they can be used for both classification and regression purposes (i.e. for discrete and continuous cases). In the tree, splits are created by identifying the most significant variable that results in homogeneous data subsets (i.e. the observations within a subset have the same/most similar response):
- Place the most significant variable at the top (the so-called root) of the tree;
- Split the data into two subsets such that each subset contains data with the same value for an attribute;
- Repeat steps 1 and 2 until you end up in a terminal node and can no longer make any splits.
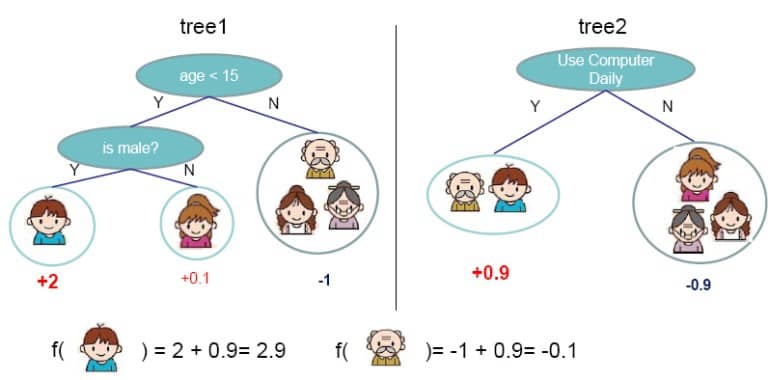
However, if there are many predictors (independent variables), the tree will become very complex and might very well overfit the data. In order to avoid overfitting, one could ‘prune’ the tree (i.e. cutting away the lower leaves). A visual representation of two simple decision trees can be found in the figure below.
Random forest
A random forest combines multiple decision trees, where the outcome is the most-frequent occurring label (in classification) or the average of outputs by different trees (in regression). There are two main differences compared with the traditional decision tree algorithm: first of all, the observations are taken with replacement (resulting in a so-called Bootstrap sample). Secondly, the traditional algorithm is improved by decorrelating trees: whenever a split should be made in a tree, only a part of the total predictors (i.e. variables) is considered. While this might not seem to be an improvement over the traditional algorithm, as clearly a single tree will not be able to predict as it did before, decorrelating trees ensures that the trees are not so similar to each other and, as a result, the total variation is lower. Therefore, the total collection of trees (the so-called random forest) is more reliable.
(k-fold) cross validation
When we for instance consider combining decision trees, the number of trees that we work with is important: a too small number of trees usually implies a less accurate prediction rule (as there have not been enough rules/trees to learn from), while a too high number of trees can result in overfitting. This number is therefore often selected using k-fold cross-validation: k-fold cross-validation involves partitioning the data into k folds, where k − 1 folds are used as training set and the remaining one is used as validation set for which the Mean Squared Error (MSE) is calculated. This procedure is repeated k times, where each time a different group of observations is treated as validation set. Finally, the k-fold cross validation estimate equals the average of all k validation MSEs. This procedure is not only applied for decision trees, but also for other machine-learning methods.
Regularization
Regularization, which is also known as shrinkage, aims to decrease the number of predictors/variables in a regression model, thereby reducing the model’s variance and the probability of overfitting. Regularization fits a model on all the possible predictors, but imposes a penalty on the variables such that the less relevant coefficients are shrunken towards zero. Depending on the type of shrinkage, the coefficients may even be estimated to exactly zero, such that variable selection is performed. The two best-known techniques for shrinking the regression coefficients towards zero are called ridge regression and the lasso.
Principal component analysis
Principal component analysis (PCA) is one of the most popular dimension reduction techniques, where correlated variables are combined in order to reduce the total amount of features. One can imagine that modeling a data set that contains a large amount of variables is very computationally inefficient, and hence PCA can be used to reduce the number of variables without losing too much valuable information. This is done by combining possibly correlated variables into a set of linearly uncorrelated variables (called principal components) and selecting only the ones that explain most of the data’s variance.
Text by: Ennia Suijkerbuijk


